From College to Google's Hidden Tech Treasure: The Ultimate File System Unveiled!
Designed to handle mind-boggling amounts of information and operate seamlessly across countless servers, GFS is the unsung hero behind the scenes of your favorite Google services.

Welcome to the fascinating world of Google File System (GFS), the behemoth that powers the internet giant's immense data infrastructure! Designed to handle mind-boggling amounts of information and operate seamlessly across countless servers, GFS is the unsung hero behind the scenes of your favorite Google services.
Imagine managing and storing petabytes of data across thousands of machines while ensuring fault tolerance and optimal performance - that's exactly the challenge Google tackled with GFS. This distributed file system, born out of necessity to handle Google's ever-growing data requirements, holds the key to understanding how modern tech giants keep their colossal data centers in check.
In this blog article, we'll embark on an exciting journey into the technical depths of Google File System. We'll uncover the ingenious architecture that enables it to function flawlessly, the smart strategies used for data replication, and the tricks up its sleeve to recover from failures without skipping a beat.
Whether you're a recent graduate or an aspiring tech enthusiast, get ready to immerse yourself in the world of cutting-edge technology as we peel back the layers of Google's extraordinary file system. Let's dive in!
A bit of history lesson...
The history behind Google File System (GFS) traces back to the early 2000s when Google was experiencing exponential growth in terms of data storage requirements. During this time, traditional file systems and storage solutions were unable to cope with the massive scale and reliability demands posed by Google's rapidly expanding services.
In 2003, three brilliant minds at Google - Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung - took on the challenge of building a highly scalable, fault-tolerant, and distributed file system. The result of their efforts was GFS, a groundbreaking innovation that would redefine how large-scale data storage and processing were managed.
Key Objectives:
Scalability: GFS aimed to handle an ever-increasing volume of data by distributing it across multiple servers, allowing Google's infrastructure to grow seamlessly as more data was generated.
Fault Tolerance: The system needed to account for hardware failures, which were inevitable at such a large scale. GFS was designed to provide continuous and reliable data access even if individual servers experienced issues.
High Performance: Google required a file system that could support large files and high read/write throughput, essential for serving search results and other web services efficiently.
Main Features:
Chunking: GFS broke down files into fixed-size chunks, typically 64 MB in size. Each chunk was independently replicated across multiple servers to ensure data availability and fault tolerance.
Master-Chunkserver Architecture: GFS adopted a master-slave architecture. The master node, known as the "master," kept track of metadata like file locations, while the "chunk servers" stored and managed the actual data.
Replication and Data Consistency: Each chunk was replicated across multiple chunk servers to ensure data redundancy and reliability. The system employed a well-coordinated replication strategy to maintain data consistency.
Automatic Recovery: GFS incorporated automatic recovery mechanisms to handle server failures. When a chunk server failed, the master redistributed its chunks to other servers to maintain data availability.
Impact and Legacy:
Google File System was a game-changer in the world of distributed file systems. Its innovative approach and practical implementation demonstrated the viability of large-scale distributed storage systems, paving the way for subsequent systems like Hadoop Distributed File System (HDFS) and others.
The concepts and lessons learned from GFS heavily influenced the development of other big data technologies and significantly shaped the modern cloud computing landscape. Today, GFS continues to serve as a foundational building block for Google's impressive data infrastructure, contributing to the seamless functioning of various Google services we use every day.
Lets talk about a high level design...
The basic concept of GFS is that a single file is broken into multiple smaller pieces or chunks and distributed in multiple commodity servers. A single chunk of a file is replicated in multiple places for redundancy. A master server controls the entire flow of data through the system. Lets take each piece and talk a bit more in depth.
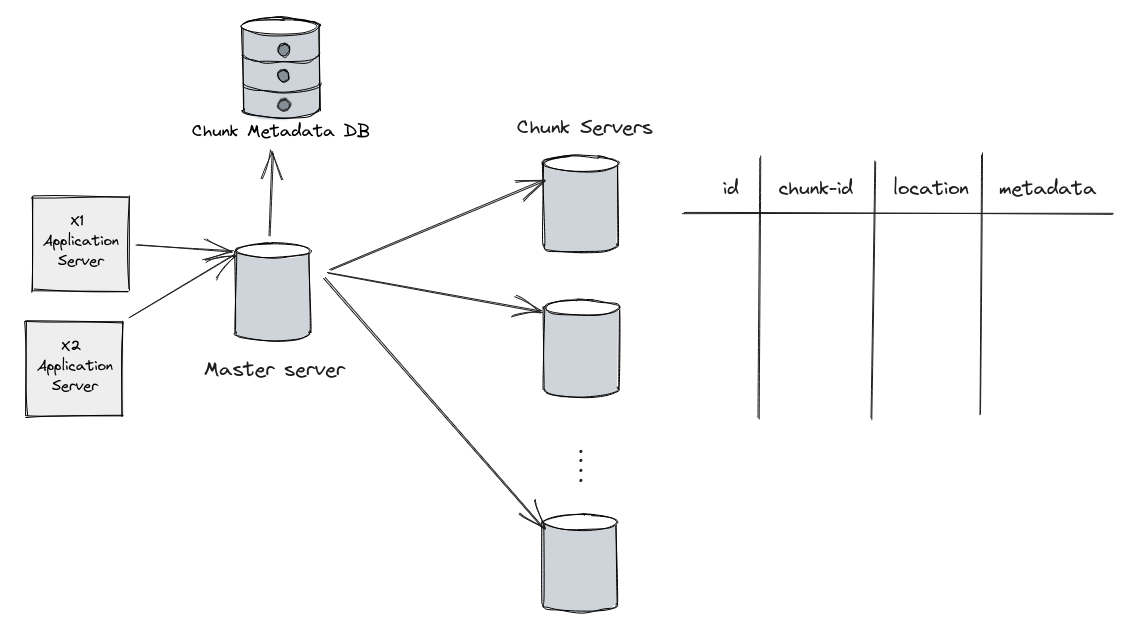
- Clients: At the top level, there are multiple client machines that interact with the GFS to read and write data. These clients access the file system through a client library, which handles communication with the GFS master and chunk servers.
- Master Node: The Master node is the central control and metadata management component of GFS. It keeps track of the overall file system namespace, including file and chunk metadata. The Master maintains mapping information to identify which chunks belong to which files and tracks the location of each chunk on different chunk servers.
- Chunk Servers: The chunk servers are responsible for storing actual data chunks. Each chunk server is equipped with local storage to store the chunks and replicate them as required. GFS divides large files into fixed-size chunks (e.g., 64 MB), and each chunk is identified by a unique handle.
- Chunk Replication: To ensure data availability and fault tolerance, GFS replicates each chunk on multiple chunk servers. The replication factor is configurable, typically set to three, meaning each chunk has three replicas spread across different chunk servers.
- Secondary Master (Optional): For increased reliability, GFS can optionally have a Secondary Master. The Secondary Master replicates the functionality of the primary Master and can take over in case the primary Master fails.
- Snapshot Master (Optional): In some setups, there might be a Snapshot Master, responsible for handling periodic snapshots of the file system to provide data consistency and backup capabilities.
Data Flow and Operations:
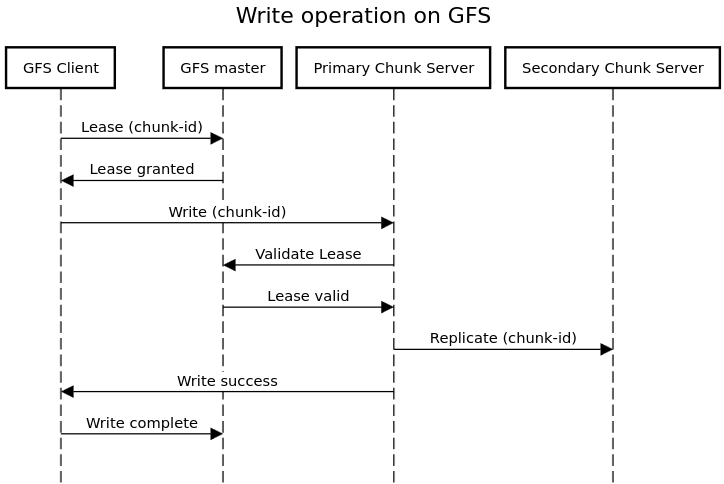
- File Write: When a client wants to write data, it communicates with the Master to get the locations of the available chunk servers. The client then writes the data to the identified chunk servers, and the chunk servers replicate the data to other replicas.
- File Read: For a read operation, the client first contacts the Master to obtain the locations of the relevant chunks. The client then reads the data directly from the appropriate chunk server.
- Failure Handling: GFS is designed to handle chunk server failures gracefully. If a chunk server becomes unavailable, the Master detects the failure and coordinates the re-replication of the chunks hosted on that server to other available chunk servers.
- Consistency and Synchronization: GFS employs mechanisms to maintain data consistency across replicas, ensuring that all replicas of a chunk are in sync. This consistency is crucial for reliable data retrieval.
Remember that the actual implementation and architecture of GFS may have evolved since its inception. Nevertheless, this high-level design captures the fundamental components and interactions in the system.